Deployment Options
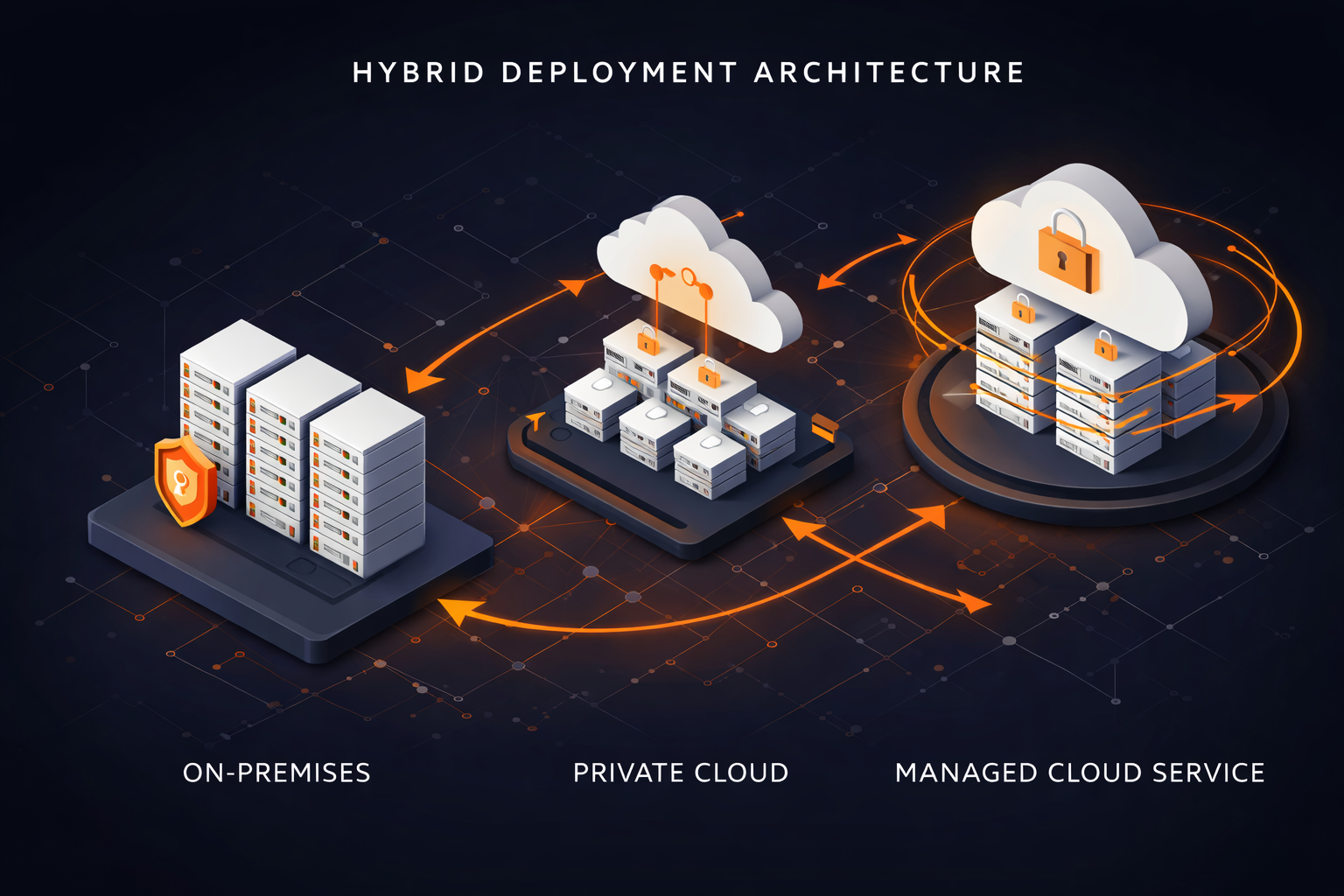
On-Premises
Deploy Malta Cortex on your own servers for complete control and data sovereignty.
- Full infrastructure control
- No data leaves your network
- Custom security policies
- Kubernetes or Docker support
Private Cloud
Deploy on your private cloud infrastructure with managed support from Malta Solutions.
- AWS, Azure, GCP support
- Dedicated infrastructure
- Managed updates & patches
- Compliance & security
Malta Managed Cloud
Let us handle everything. Enterprise-grade infrastructure with 24/7 support.
- Premium GPU hardware
- Global data centers
- 99.9% uptime SLA
- Fully managed service